SQL 함수
개요
SQL에도 함수는 있다.
즉, 어떤 것을 넣고 값을 반환 받는 것이다.
이 함수들을 활용해 다양한 쿼리를 날리는 게 가능해진다.
사용자 정의를 통해서 함수를 만들 수도 있고, dbms에 내장 구현된 함수도 있다.
또 결과값이 어떻게 나오냐로 스칼라 함수, 단일 행 함수, 다중 행 함수 등으로 분류할 수 있다.
자세한 정리는 이후에 조금 더 구체적으로 해보겠다.
스칼라 함수
행을 받으면, 해당 행의 집계되는 연산을 실행하는 함수라 대체로 하나의 값만을 반환한다.
집계 함수
가장 대표적인 것은 all, disctinct.
나머지는 대체로 통계로 활용될 수 있는 함수들이다.
count, sum, avg, max, min, stddev, varian
이때 count는 *를 쓸 경우 모든 행을 세는데 특정 값을 넣으면 null 아닌 해당 컬럼의 개수를 센다.
흔히 group by와 엮어서 쓰는 함수들이다.
group by와 함께 쓰여야만 하는 함수도 있고, 아닌 함수도 있다.
group by가 걸린다면 하나의 결과만 나오지는 않고 나누어진 행들에 대해 각각 하나의 값을 출력한다.
이것은 특정하게 묶인 그룹들에 대해서 각각 한 행의 결과를 리턴한다.
select, having, order by 절에 올 수 있다.
윈도우 함수
윈도우 함수는 행들의 관계에 대해 세밀한 결과를 지정할 수 있는 함수이다.
select 문에서 결과를 꺼낼 때 우리는 집계를 해서 한 행으로 나오던 것을 스칼라 값으로 줄일 수 있다.
근데, min, avg, sum 등이 있는 것은 좋다.
그런데 만약 조금 더 세밀하게 값을 뽑고 있다면 어떻게 할까?
가령 두번째로 작은 놈을 추출하고 싶은 것이다.
아니면 사람을 키순으로 정렬한 후에 키를 뽑는 게 아니라 그 사람의 이름을 뽑고 싶다.
몇가지 예약어들을 보자.
- 순위 산정 방식
- rank
- 지정한 기준에 따라 순위를 구한다.
- 동일 순위가 있다면 다음 순위는 그만큼 건너 뛴다.
- 1등, 2등,2등이 있으면 그다음은 4등이다.
- dense_rank
- 동일 순위 이후에 건너뛰지 않고 순위를 표시한다.
- 2등이 두명이면 다음은 3등.
- row_number
- 동일 순위가 있어도 무조건 순서대로 간다.
- 같은 점수가 있어도 둘은 다른 순위가 부여된다.
- rank
- 집계 방식
- sum, max, min, avg, count
- 행순서
- first_value, last_value
- 지정 기준에서 가장 앞이나, 뒤의 값을 구한다.
- lag
- 지정 기준에서 이전값
- lead
- 지정 기준에서 이후값
- first_value, last_value
- 그룹 내 비율
- cume_dist
- 누적백분율 구하기.
- 누적이 되니 최종행에선 1이 나온다.
- percent_rank
- 각 행의 순서별 백분율.
- 제일 먼저 온 게 0, 늦게 나온 게 1이다.
- ntile
- 특정 값으로 n등분하기
- ratio_to_report
- 각 행이 차지하는 비율.
- cume_dist
뭐가 많아서 어지럽다..
그럼 문법은 어떻게 되나?
윈도우함수(인자) over (partition by 컬럼 order by 컬럼)
이게 가장 기본적인 형식이다.
위에서 본 함수들이 윈도우함수고, 출력하고 싶은 놈이 인자에 들어간다.
over는 반드시 등장해야 하는데, 아무튼 뒤에 놈은 그룹화를 어떻게 할지, 정렬을 어떻게 할지를 나타낸다.
윈도우함수(인자) over (partition by 컬럼 order by 컬럼)
윈도우절(rows|range between
unbounded preceding|current row
and unbounded following|current row
)
아래에 이렇게 윈도우 절을 붙이는 것도 가능하다..
윈도우 함수가 처리되는 행 범위를 지정할 수 있다!
일단 rows는 물리적 결과 행 수를 나타낸다.
range는 논리적인 값 범위를 나타낸다.
between은 행 범위 시작과 끝을 나타낸다.
이 범위 시작 끝을 자유롭게 설정할 수 있는데,
unbounded를 붙이면 행 전체의 첫번째나 끝을 나타낸다.
그리고 preceding, following은 나타내진 행으로부터 몇 칸 떨어진 건지 나타낸다.
점점 어지러운데, 실습을 봐야 한다.
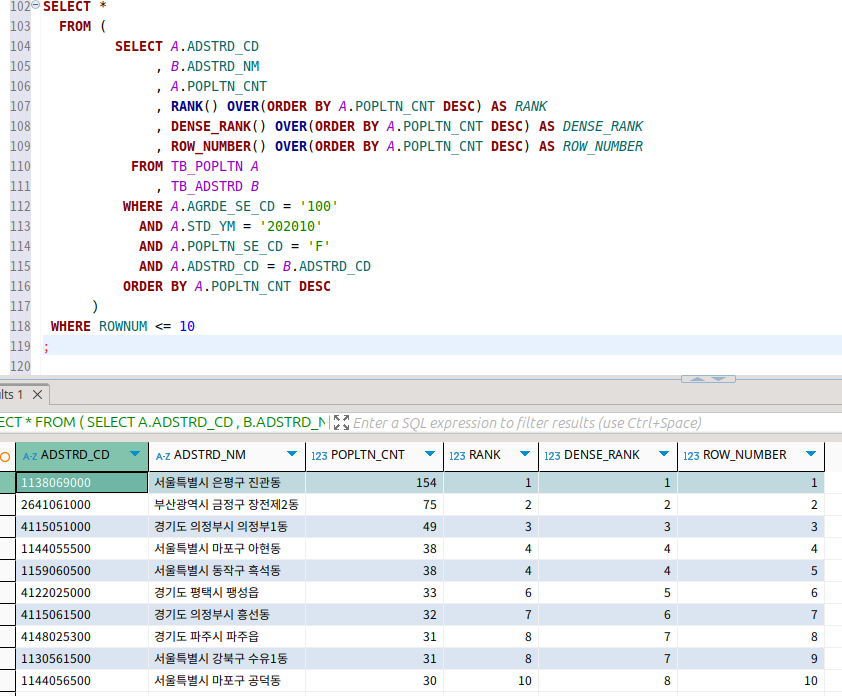
일단 가장 기본적인 형태.
순위 부분에서 각자가 지정하는 방식이 다른 게 보인다.
SELECT A.ADSTRD_CD
, A.ADSTRD_NM
, A.AGRDE_SE_CD
, A.POPLTN_CNT
, MAX(A.POPLTN_CNT) OVER(PARTITION BY A.AGRDE_SE_CD) AS 최대인구수
, MIN(A.POPLTN_CNT) OVER(PARTITION BY A.AGRDE_SE_CD) AS 최소인구수
, ROUND(AVG(A.POPLTN_CNT) OVER(PARTITION BY A.AGRDE_SE_CD), 2) AS 평균인구수
, ROUND(AVG(A.POPLTN_CNT) OVER(PARTITION BY A.AGRDE_SE_CD ORDER BY A.POPLTN_CNT ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING ), 2) AS 평균인구수_1_1
FROM
(
SELECT A.ADSTRD_CD
, B.ADSTRD_NM AS ADSTRD_NM
, A.AGRDE_SE_CD
, A.POPLTN_CNT
FROM TB_POPLTN A, TB_ADSTRD B
WHERE A.POPLTN_SE_CD = 'T'
AND A.STD_YM = '202010'
AND A.ADSTRD_CD = B.ADSTRD_CD
AND A.POPLTN_CNT > 0
AND B.ADSTRD_NM LIKE '경기도%고양시%덕양구%'
) A
;
이번에는 집계 함수들이다.
집계를 해야 하니 partition by를 사용했다.
rows 부분을 보면 위아래로 현재를 기준으로 위 아래 한 값씩 평균을 구하는 것이 보인다.
이렇게 해도 맨 첫행과 끝행에 대해서는 없는 건 없는대로 처리하니까 걱정할 필요 없다.

다른 예시.
이렇게 between을 안 넣고 하면 한쪽 기준만 이용한다.
unbounded preceding이니 맨 첫 행부터 시작해서 누계를 구하고 있는 꼴이다.
rows는 행을 기준으로 했지만, range는 order by에서 지정된 컬럼의 값을 기준으로 한다.
달리 말하자면 range를 사용하려면 무조건 order by가 지정돼야 한다.
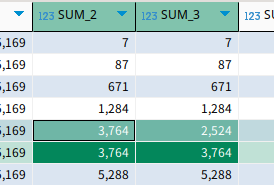
rows와 range는 이러한 차이를 일으켰다.
rows는 행을 기준으로 하기에 일단 무조건 위에서 아래로 진행하며 sum이 됐다.
그러나 range는 실제 값을 기준으로 하기에 동일한 값을 가진 행이 있을 때는 그것을 포함해서 계산했다.
해당 두 행에서 나와야 할 값이 1240으로 동일했기에 range에서는 current에 해당하는 1240명을 두번 계산해서 앞선 행부터 3764가 나온 것이다.
range는 이렇게 현재 행을 기준으로 order by 컬럼의 값을 참고하고, 거기에서 범위를 나눈다.
그러니 range는 연속 데이터 컬럼이 꼭 있어야 한다는 점도 특징이 될 수 있겠다.
SELECT A.SUBWAY_STATN_NO AS 지하철역번호
, (SELECT L.TK_GFF_SE_NM
FROM TB_TK_GFF_SE L
WHERE L.TK_GFF_SE_CD = B.TK_GFF_SE_CD
) AS 승차구분명
, B.TK_GFF_CNT AS 승하차횟수
, FIRST_VALUE(B.TK_GFF_CNT ) OVER(PARTITION BY B.TK_GFF_SE_CD ORDER BY B.BEGIN_TIME ROWS UNBOUNDED PRECEDING ) AS FIRST_VALUE
, LAST_VALUE(B.TK_GFF_CNT ) OVER(PARTITION BY B.TK_GFF_SE_CD ORDER BY B.BEGIN_TIME ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS LAST_VALUE
, LAG(B.TK_GFF_CNT , 1) OVER(PARTITION BY B.TK_GFF_SE_CD ORDER BY B.BEGIN_TIME ) AS LAG
, LEAD(B.TK_GFF_CNT , 1) OVER(PARTITION BY B.TK_GFF_SE_CD ORDER BY B.BEGIN_TIME) AS LEAD
FROM TB_SUBWAY_STATN A
, TB_SUBWAY_STATN_TK_GFF B
WHERE A.SUBWAY_STATN_NO = '000031'
AND A.SUBWAY_STATN_NO = B.SUBWAY_STATN_NO
AND B.BEGIN_TIME BETWEEN '0700' AND '1000'
AND B.END_TIME BETWEEN '0800' AND '1100'
AND B.STD_YM = '202010'
ORDER BY B.TK_GFF_SE_CD, B.BEGIN_TIME
;
이번에는 lag, lead 함수.
lag와 lead는 원래 나올 행에서 몇 행 뒤, 혹은 앞에 있는 행을 보여준다.
참고로 preceding 쪽만 조건을 걸고 싶을 때는 저렇게 between을 없애고 그것만 적어줘도 된다.
그런데 following 쪽을 적을 때는 반드시 between을 다 적어야 한다.
현재 행부터 끝까지를 나타내고 싶다면 current row라고 적어주면 된다.
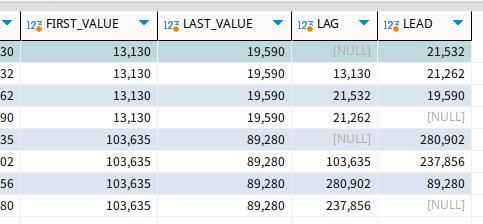
결과는 이렇게 나왔다.
한 행 앞과 뒤를 출력하게 걸어뒀기에 맨 첫놈과 끝놈만 null이 적힌다.
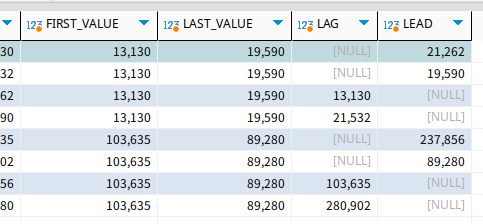
lag와 lead에 2를 넣으니 두칸 밀려서 출력하는 것이 보인다.
lag와 lead는 그 자체로 행에 대한 연산을 한다.
그래서 여기에는 rows나 range가 들어갈 수가 없다.
어차피 현재행을 기준으로 하는 연산이라 저게 들어가면 의미도 불명확해진다.
SELECT A.SUBWAY_STATN_NO AS 지하철역번호
, (SELECT L.TK_GFF_SE_NM
FROM TB_TK_GFF_SE L
WHERE L.TK_GFF_SE_CD = B.TK_GFF_SE_CD ) AS 승차구분명
, B.TK_GFF_CNT AS 승하차횟수
, ROUND(RATIO_TO_REPORT(B.TK_GFF_CNT) OVER(PARTITION BY B.TK_GFF_SE_CD), 2) AS RATIO_TO_REPORT
, ROUND(PERCENT_RANK() OVER(PARTITION BY B.TK_GFF_SE_CD ORDER BY B.TK_GFF_CNT ), 2) AS PERCENT_RANK
, ROUND(CUME_DIST() OVER(PARTITION BY B.TK_GFF_SE_CD ORDER BY B.TK_GFF_CNT ), 2) AS CUME_DIST
, ROUND(NTILE(2) OVER(PARTITION BY B.TK_GFF_SE_CD ORDER BY B.TK_GFF_CNT ), 2) AS NTILE
FROM TB_SUBWAY_STATN A
, TB_SUBWAY_STATN_TK_GFF B
WHERE A.SUBWAY_STATN_NO = '000031'
AND A.SUBWAY_STATN_NO = B.SUBWAY_STATN_NO
AND B.BEGIN_TIME BETWEEN '0700' AND '1000'
AND B.END_TIME BETWEEN '0800' AND '1100'
AND B.STD_YM = '202010'
ORDER BY B.TK_GFF_SE_CD , B.TK_GFF_CNT
;
마지막으로 그룹 내 비율을 따지는 함수들.
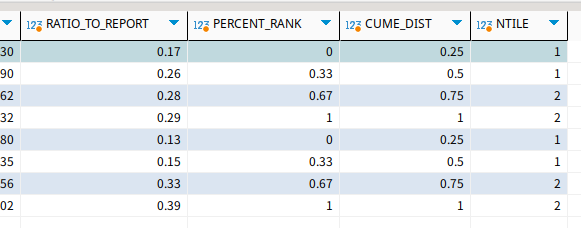
결과는 이렇게 나온다.
ratio_to_report는 그룹 내 비율이 나온다.
지금 group by로 절반이 나뉜 건데, 아무튼 첫행은 첫 그룹의 17퍼를 차지하는 게 보인다.
percent_rank는 정렬 후 순서 퍼센티지를 나타낸다.
정렬을 하고 나서 상위 33퍼가 두번째행까지 속한다는 것이다.
cume_dist도 동일하다. 다만 자기자신을 포함해서 비율을 계산한다.
perent_rank는 현재 행 앞에 얼마나 많은 퍼센티지가 있나 보는 거고, cume_dist는 현재 행 바로 뒤부터 몇 퍼센트인지를 보는 거다.
ntile은 컬럼을 전체 n등분으로 나눌 때 현재 행이 어디에 속하는지를 나타낸다.
단일행 함수
한 입력에 대해 한 출력을 내는 것을 단일행 함수라 한다.
한 벡터가 들어가면 한 벡터만 나오는 것.
select, where, order by 절에서 사용된다.
개별 값을 조작하고 개별로 값을 낸다.
중첩도 가능해서 많이 쓰이게 된다.
다음의 종류가 있고, 간략하게만 보자.
- 문자형
- lower, upper, substr, length, ltrim, rtrim, trim, ascii
- 숫자형
- abs, mod, round, trunc, sign, chr, ceil, floor, exp, log, ln, power, sin, cos, tan
- 날짜형
- sysdate, extract, to_number
- 변환형
- to_number, to_char, to_date, convert
- null 관련
- nvl, nullif, coalesce
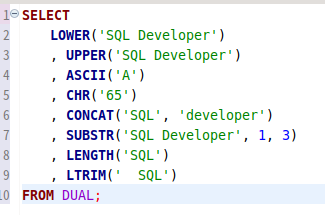
이것들이 문자형의 예시.
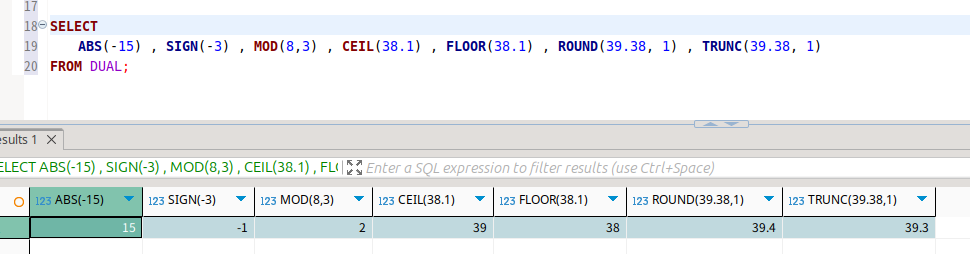
이건 숫자형.
sign은 부호를 판별한다.
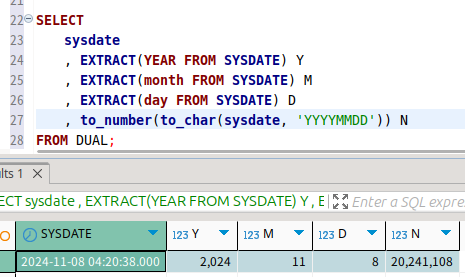
이게 날짜형이다.
날짜 형에는 extract와 to_char를 사용할 수 있다.
보니까 to_number는 그 자체로 sysdate를 받지 못한다.
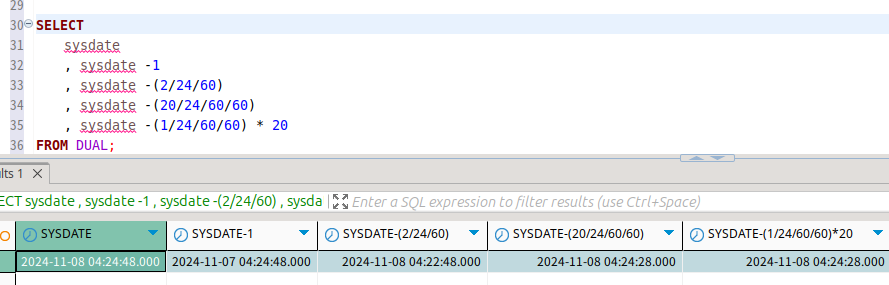
날짜는 이런 식으로 숫자 연산이 가능하다.
기본으로는 하루를 빼고, 뒤에 값을 넣을 수록 단위를 작게 할 수 있다.
변환형은 위에서 본 to 시리즈가 있다.
convert는 원하는 형태로 바꿀 수 있는데, 날짜형은 내가 원하는 방식으로 바꿀 수 있게 해준다고 하는데..
찾아보니 오라클에서 convert는 문자열의 타입 변환만 시키는 녀석인가보다.
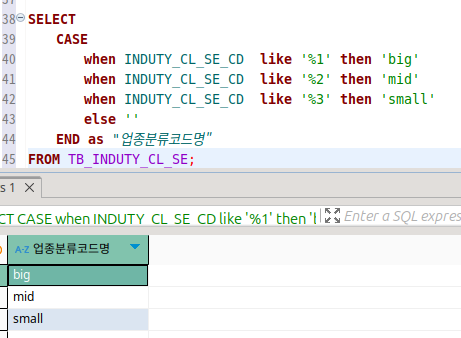
case 도 단일 행으로 표현 가능한 방식이다.
정확히는 함수는 아닌 것 같다.
오라클에서는 여기에서 별칭을 붙일 때 무조건 큰따옴표로 해야 한다...
아예 따옴표를 넣지 말던가.
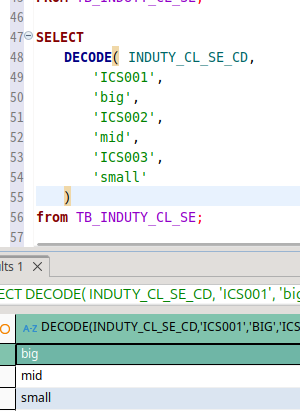
이런 식으로 decode로 나타내는 방법도 있다.
이 방법은 switch문처럼 쓰기에 용이해보인다.
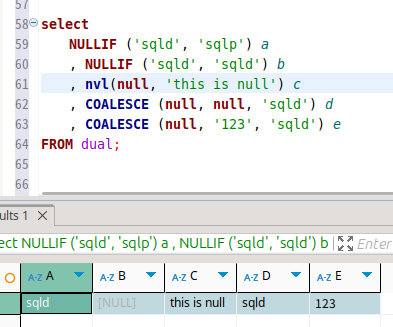
마지막으로 null 관련 함수.
coalescse는 첫번째로 null 아닌 값을 리턴한다.
nullif는 뒤의 값과 같은 녀석들을 null로 만드는 함수이다.
다중 행 함수
기타
DML#그룹 함수라는 게 있다.
이건 group by에서만 사용되는 함수라 그쪽에 정리했다.